Was ist OCR-Software? Das ist ein gängiger Suchbegriff in der Google-Suche, und selbst von Buchhaltern wird diese Frage regelmäßig gestellt. OCR ist eine Technik, die weltweit weit verbreitet ist, oft ohne dass man es merkt. In diesem Blogbeitrag erkläre ich, wie sie funktioniert und was die wichtigsten Vorteile sind.
Was ist OCR?
Es ist die englische Abkürzung für „Optical Character Recognition“ oder optische Zeichenerkennung. Sie kann Zeichen aus einem Bild lesen und sie für die weitere Verarbeitung vorbereiten.
Was macht OCR-Software?
OCR-Software wird seit Jahrzehnten eingesetzt, um Bücher und Papierdokumente zu digitalisieren. Ein Beispiel sind Scanner und Kopierer, die mit OCR-Techniken ausgestattet sind und es ermöglichen, Papierdokumente direkt in bearbeitbare Word-Dateien zu scannen oder sie als PDF-Dateien zu speichern.
In den letzten Jahren wurden durch technische Innovationen auch neue Ziele verfügbar. Dazu gehören die automatische Erkennung von Nummernschildern, Verkehrszeichen (autonomes Fahren), Pässen und Führerscheinen (Identifizierung).
Dabei entwickelt sich der Begriff OCR-Software immer mehr zu einem Sammelbegriff von Techniken für viele verschiedene Zwecke. Ein Beispiel für einen solchen OCR-Zweck ist die Nische der Rechnungserkennung, mit der wir uns bei TriFact365 beschäftigen.
Wie funktioniert die OCR-Software?
Die Technologie ist komplex, aber eigentlich lässt sich die Technik einfach in 3 Schritten erklären: (1) Eingabe, (2) Durchsatz und (3) Ausgabe. Nun sind „Eingabe, Durchsatz, Ausgabe“ Merkmale eines offenen Systems (https://de.wikipedia.org/wiki/Open_systeem), etwas, das wir auch in TriFact365 verwenden. Anhand dieser 3 Schritte werde ich das Konzept der OCR näher erläutern:
1. Einlesen von Bildern (Eingabe)
Alles, was Sie einscannen oder abfotografieren, ist ein Bild und kann gelesen werden, vorausgesetzt natürlich, es wird im richtigen Format geliefert. Beispiele sind Bilder von: Büchern, Zeitschriften, Arbeitsanweisungen, Geschäftsdokumenten und natürlich Rechnungen.
2. Zeichenerkennung (Durchsatz)
Nachdem ein Bild geliefert wurde, erfolgt die eigentliche Erkennung der Zeichen. Diese besteht aus 3 Phasen (Quelle: https://de.wikipedia.org/wiki/Texterkennung)
In der ersten Stufe (Vorverarbeitung) prüft die OCR-Software, ob das Bild in der Größe gerade gescannt wurde, ob die Kanten glatt sind, und es werden verschiedene andere Operationen durchgeführt, um das gelieferte Bild für die nächste Stufe zu optimieren.
In der zweiten Phase betrachtet die OCR-Software das Bild auf Pixelebene und identifiziert beispielsweise Buchstaben, Zahlen und andere Satzzeichen. Die dahinter stehenden Techniken können sehr komplex sein und bestehen meist aus neuronalen Netzen und Computer-Vision-ähnlichen Techniken.
In der dritten Stufe kann die Genauigkeit weiter erhöht werden, indem die Ergebnisse durch ein Glossar (Lexikon) eingeschränkt werden. Dabei handelt es sich um eine Liste von Wörtern, die in dem Dokument vorkommen können.
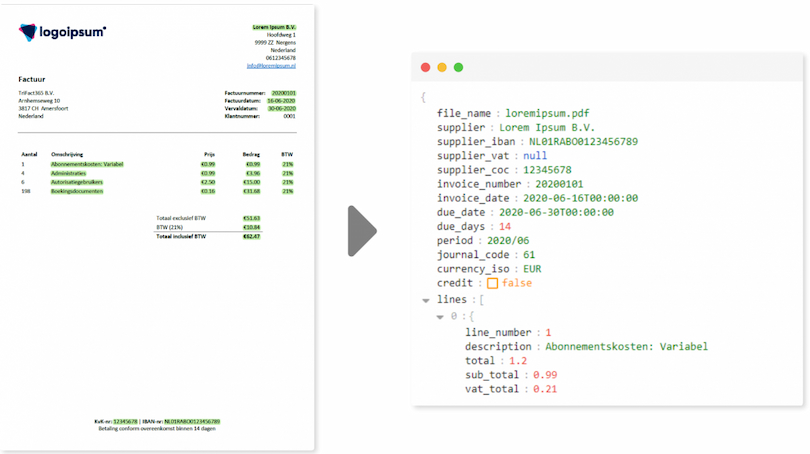
3: Export von Rohdaten (Ausgabe)
Die Ausgabe der OCR-Software (in der Regel eine Datei) kann daher Buchstaben (mehrsprachig), Zahlen und andere Zeichen enthalten. Wenn Sie also eine Rechnung durch eine OCR-Software laufen lassen, ist die Rohdatenausgabe noch kein Buchungsvorschlag. Warum eigentlich? Weil das Durcheinander von Zeichen noch keine Beziehung zu den Feldern einer Journalbuchung hat.
Benutzerdefinierte OCR-Software
Die Anbieter von OCR-Technologie sind in den letzten Jahren nicht untätig gewesen. OCR-Systeme werden zunehmend für die Verarbeitung sehr spezifischer Daten optimiert. Ich habe bereits über Anwendungen für das autonome Fahren und die Identifizierung geschrieben. Dahinter stehen Milliardeninvestitionen von Big Tech (Google, Amazon, Facebook, Apple und Microsoft) zum Beispiel, aber auch aus der Automobilbranche (autonomes Fahren) und dem Bankwesen/SaaS-Plattformen fließen weitere Investitionen in Innovationen und Start-ups.
Als niederländischer Nischenanbieter arbeiten wir bei TriFact365 auch intensiv an unserer selbst entwickelten Software für die Interpretation von OCR-Rohdaten.
Wie OCR von TriFact365 funktioniert
Alle digitalen Buchungsbelege, die bei TriFact365 eingehen, durchlaufen unsere selbstlernende Software. Ziel ist es, Rechnungen zu 100% zu erkennen und automatische Buchungsvorschläge zu generieren.
TriFact365 entwickelt eigenständig maschinelles Lernen („OCR+“), das uns in die Lage versetzt, die Erkennung von Rechnungsdaten und die Zuordnung zu Buchungsvorschlägen auf ein viel höheres Niveau zu bringen, als man es noch vor einigen Jahren für möglich hielt.
Unser OCR-Anspruch
Der Weg, den TriFact365 vor ein paar Jahren eingeschlagen hat, zahlt sich aus. Die Erkennungsraten steigen bei allen gemessenen Kunden weiter an, und unser einzigartiger Ansatz für die Erkennung von Regeln in Echtzeit ist jetzt für alle Nutzer live und zeigt vielversprechende Ergebnisse. Derzeit erreichen wir eine Leistung von rund 90 % korrekt erkannter Felder bei allen Kunden.
In Anbetracht der Änderungen, die wir noch 2021 auf den Markt bringen werden, und der vielen Innovationen, die wir für 2022 und 2023 bereits in der Pipeline haben, erscheint es uns realistisch, dass die Rechnungserkennung in den nächsten 2 Jahren über 95 % liegen wird. Unser Ziel ist es, mit selbstlernender OCR-Software eine Rechnungserkennung von über 99 % zu erreichen.
Die oben genannten Messungen werden durch unsere internen Messungen und Berichte untermauert. Unser Team von OCR-Spezialisten kommt zu dem Schluss, dass bereits ein Teil der Rechnungen zu 100 % fehlerfrei verarbeitet wird. Daher wird die „automatische Rückbuchung“ als Verbesserung auf der Expo 2021 angekündigt.
4 Vorteile der TriFact365 OCR-Software
Die TriFact365-Software enthält eine superschnelle und selbstlernende OCR-Software, die Seiten verarbeiten und in einem Bruchteil einer Sekunde eine Rohausgabe mit Interpunktion erzeugen kann. Als Benutzer werden Sie keine dieser Techniken unter der Haube bemerken und die folgenden Vorteile genießen.
Vorteil 1: Automatisches Konvertieren von Dateien in das richtige OCR-Format
Manche Nutzer scannen im PDF-Format, andere im JPG- oder TIFF-Format. Als universelles Einreichungsportal akzeptiert TriFact365 daher neben dem PDF-Format auch Word, Excel und alle gängigen gescannten Dateiformate. TriFact365 konvertiert diese automatisch in ein für unsere OCR-Software lesbares Format. Also keine Aktionen, TriFact365 kümmert sich um alles für Sie.
Vorteil 2: Alle Dateien werden von der OCR-Software gelesen
Bei TriFact365 werden alle eingehenden Belege sofort nach Anlieferung von unserer OCR-Software gelesen. Die Zuordnung der Belege nach der Erfassung („Tagging“) wird somit automatisiert, was wiederum Arbeitsschritte und damit Zeit bei der Bearbeitung von Buchhaltungsbelegen spart.
Vorteil 3: OCR-Software für alle Geschäftsdokumente geeignet
Zur Zeit werden hauptsächlich Buchhaltungsdokumente wie Eingangsrechnungen, Verkaufsrechnungen und Quittungen mit OCR verarbeitet. Dies soll auf Geschäftsdokumente wie Verträge, Jahresabschlüsse usw. ausgeweitet werden, die dann durchsuchbar gemacht werden.
Vorteil 4: Kombinieren Sie die OCR-Ausgabe (Daten) mit maschinellem Lernen (KI) und generieren Sie automatische Buchungsvorschläge bis auf Zeilenebene.
Durch die Anwendung von OCR im großen Stil mit maschinellem Lernen präsentiert unsere Cloud-Software innerhalb von Sekunden genaue Buchungsvorschläge (Journaleinträge). Danach müssen Sie nur noch eine Sichtprüfung durchführen und mit einem Klick haben Sie die Rechnung im Handumdrehen in Ihrer Buchhaltung verbucht. Hilfreiche Funktionen ermöglichen es Ihnen, den Prozess der Rechnungsbearbeitung noch reibungsloser zu gestalten.